The goal of the program is to be able to input the flower's sepal length, sepal width, petal length, and petal width, and have it output the correct flower type.
The iris data comes in the following format:
5.1,3.5,1.4,0.2,Iris-setosa
6.1,2.9,4.7,1.4,Iris-versicolor
4.7,3.2,1.3,0.2,Iris-setosa
5.8,2.7,5.1,1.9,Iris-virginica
5.0,3.6,1.4,0.2,Iris-setosa
...
where the commas are indicating
sepal length (cm), sepal width (cm), petal length (cm), petal width (cm), flower type
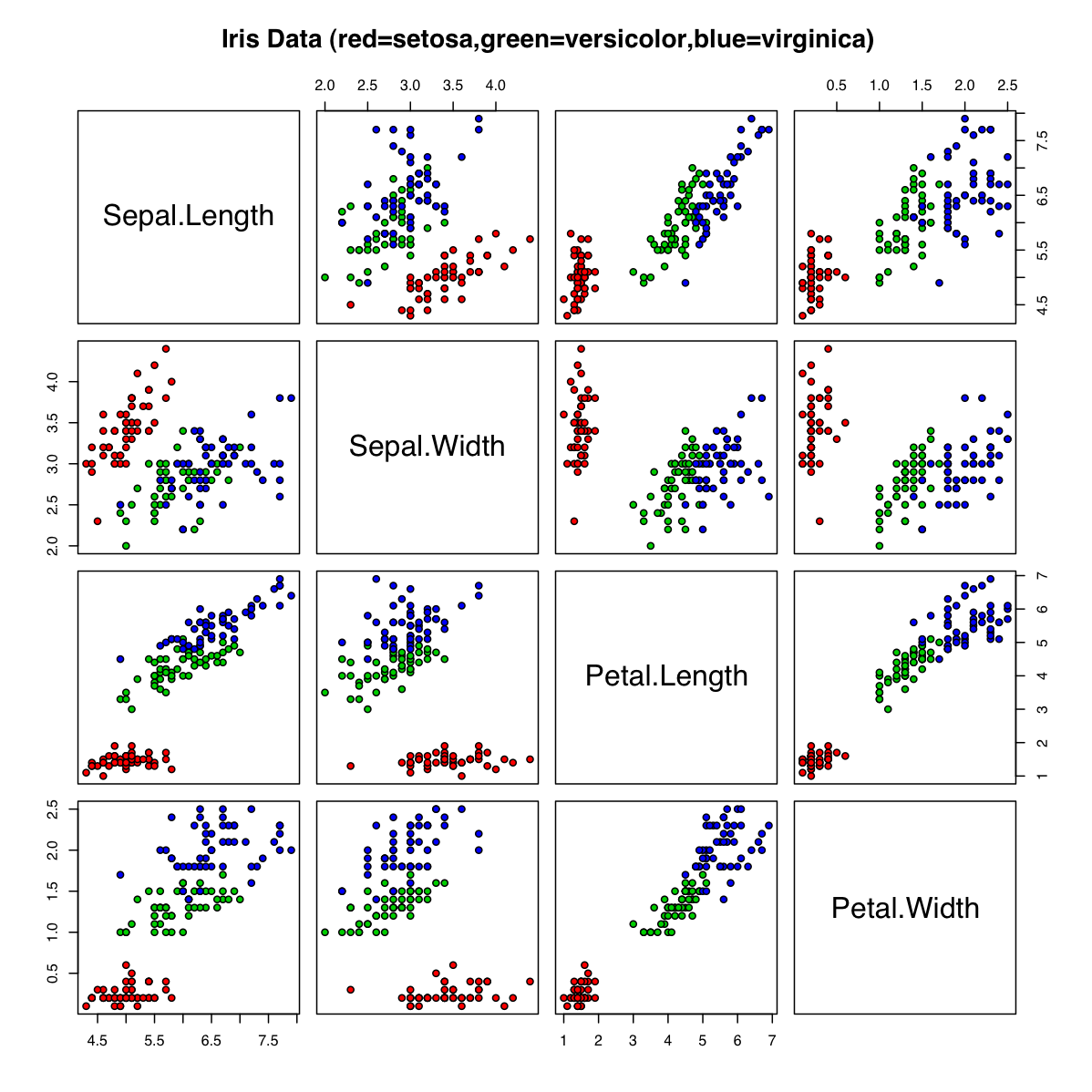
There are three different flowers in the data set, setosa, versicolor, and virginica. They look pretty similar, right?
 |
| Iris-setosa (Source: Wikimedia commons) |
 |
| Iris-versolor (Source: Wikimedia commons) |
 |
| Iris-virginica (Source: Wikimedia commons) |
 |
| (Source: Wikimedia commons by user Indon) |
----------------------------------
Algorithm Implementation
For the actual predicting, I'll be implementing logistic regression by batch gradient descent from scratch to predict Iris flower types from their sepal and petal sizes. It sounds like a handful, but the algorithm is actual quite elegant.
Given a column vector of targets y and a vector of training targets x the algorithm can be written as
1. Initialize random θ as the set of parameters
2. Until θ converges{
θ[j] := θ[j] + sum( ( y - h(x)) * x[j]) )
}
where h(x) is the sigmoid function; h(x) = 1 / ( 1 + e^(x * θ))
I don't have enough room to explain why the algorithm works, but that's a blog post for later.
Once vector θ is trained, h(x) = 1 / ( 1 + e ^ (x*θ)) will output the probability that y is the positive case.
The problem with the algorithm is that y can only be 1 or 0, positive or negative, not 3 flower types here. To solve this problem, three parameters θ are trained for each of the flowers using the one vs. all method.
In python, I used the popular numerical processing library numpy so I could do vector operations much easier.
To set up the batch gradient descent, I made some smaller functions (numpy imported as np):


-------------------------------------------
Results
The original data set of the the iris flowers provides 150 examples, so I used 120 for training the classifier and the other 30 for testing.
Unfortunately, the trained classifier actually did very poorly. When I tested it, it would either get 60 - 80% correct, or 0-20%, which is peculiar. I think it had something to do with the convergence testing which I must have messed. Of course, I only used linear features, which is also a problem. After all the debugging I had to do in the program, I think I'll call it finished.
The code is hosted on github at https://github.com/liu916/IrisTrain